
Cloudflare says it lost 55% of logs pushed to customers for 3.5 hours

Internet security giant Cloudflare announced that it lost 55% of all logs pushed to customers over a 3.5-hour period due to a bug in the log collection service on November 14, 2024.
Cloudflare offers an extensive logging service to customers that allows them to monitor the traffic on their site and filter that traffic based on certain criteria.
These logs allow customers to analyze traffic to their hosts to monitor and investigate security incidents, troubleshooting, DDoS attacks, traffic patterns, or to perform site optimizations.
For customers who wish to analyze these logs using external tools, Cloudflare offers a “logpush” service that collects logs from its various endpoints and pushes them out to external storage services, such as Amazon S3, Elastic, Microsoft Azure, Splunk, Google Cloud Storage, etc.
These logs are generated at a massive scale, as Cloudflare processes over 50 trillion customer event logs daily, of which around 4.5 trillion logs are sent to customers.
A cascade of failsafe failures
Cloudflare says a bug in the logpush service caused customer logs to be lost for 3.5 hours on November 14.
“On November 14, 2024, Cloudflare experienced an incident which impacted the majority of customers using Cloudflare Logs,” explains Cloudflare.
“During the roughly 3.5 hours that these services were impacted, about 55% of the logs we normally send to customers were not sent and were lost.”
The incident was caused by a misconfiguration in Logfwdr, a key component in Cloudflare’s logging pipeline responsible for forwarding event logs from the company’s network to downstream systems.
Specifically, a configuration update introduced a bug that issued a ‘blank configuration,’ wrongly telling the system that there were no customers whose logs were configured to be forwarded, and thus the logs were discarded.
Logfwdr is designed with a failsafe that defaults to forwarding all logs in case of ‘blank’ or invalid configurations to prevent data loss.
However, this failsafe system caused a massive spike in the volume of logs being processed as it attempted to forward logs for all customers.
It overwhelmed Buftee, a distributed buffering system that holds logs temporarily when downstream systems cannot process them in real-time, which was called to handle 40 times more logs than its provisioned capacity.
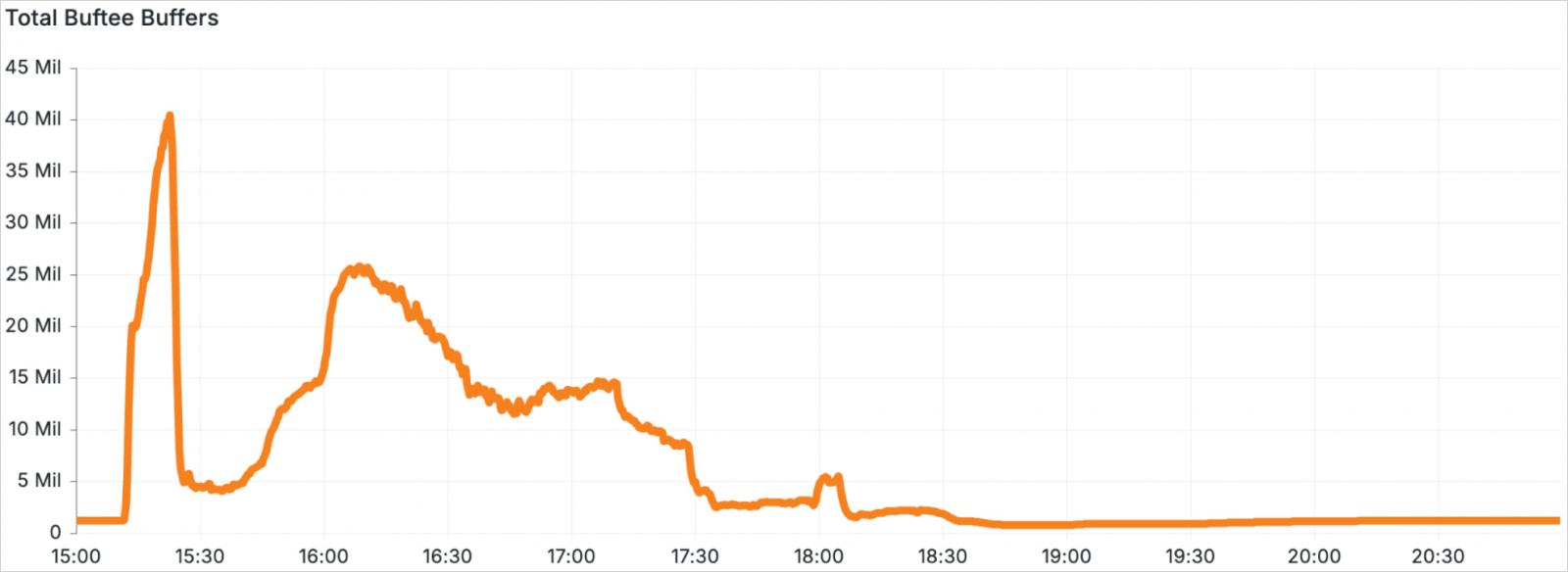
Source: Cloudflare
Buftee features its own set of buffer overload safeguards like resource caps and throttling, but these failed due to improper configuration and lack of previous testing.
As a result, within just five minutes of the misconfiguration in Logfwdr, Buftee shut down and required a complete restart, further delaying recovery and resulting in the loss of even more logs.
Stronger measures
In response to the incident, Cloudflare has implemented several measures to prevent future occurrences.
This includes the introduction of a dedicated misconfiguration detection and alerting system to notify teams immediately when anomalies in log forwarding configurations are spotted.
Moreover, Cloudflare says it has now correctly configured Buftee to prevent spikes in log volumes from causing complete system outages.
Finally, the company plans to routinely conduct overload tests simulating unexpected surges in data volumes, ensuring that all steps of the failsafe mechanisms are robust enough to handle these events.
Source link
lol
Internet security giant Cloudflare announced that it lost 55% of all logs pushed to customers over a 3.5-hour period due to a bug in the log collection service on November 14, 2024. Cloudflare offers an extensive logging service to customers that allows them to monitor the traffic on their site and filter that traffic based…